编码以及中文乱码
参考自B站柴知道,十分推荐观看原视频,侵权请联系删除。
什么是编码
计算机存储的内容都是二进制的数据,图像、音频、文字等也都需要按照一定的规则转换成二进制数据进行存储。将文字转换成二进制数据的规则就叫做编码。
假如世界上只有三个文字“柴知道”,那么我们就可以按照下面的方式进行编码:

ASCII编码
计算机存储中最小的单位是一个字节(byte),一个byte等于8bit,因此一共可以编码2^8=256个字符。美国最先使用计算机,它们使用的文字只有26个英文字母,完全足够了。因此他们按照下面的方式对英文字母进行了编码,同时还包含了一些特殊控制符号(如回车、换行、删除),一共用了128个。所以只用了7bit(2^7=128),所以最高位置0。
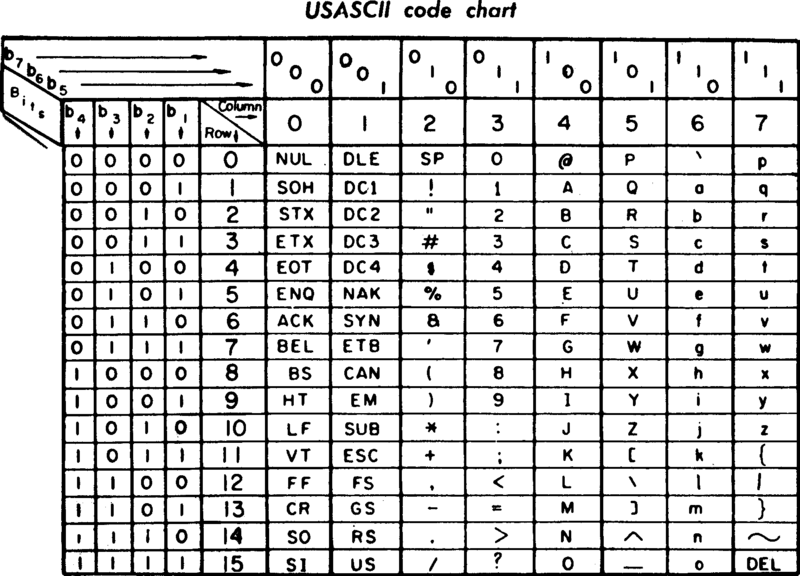
比如,字母a对应的码位就是01100001,十六进制为0x61。z对应的码位为01111010,十六进制为0x7A。
下面的代码,我们将通过手动构造二进制数据,然后输出得到字符串"hello world"。
1 |
|
GB2312编码
ASCII只能编码英文字母和数字,而且一个byte最多只能编码256个字符,那么怎么来编码中文呢?GB2312-80就是1980年公布的汉字编码国家标准,采用两个byte来编码字符。如果是ASCII码已经存在的字符(如字母、数字),仍按照原有的方案用一个byte来编码,如果是汉字则使用2byte来编码。

从上图中可以看出,hello仍然按照ASCII的编码方法编码成68 65 6c 6c 6f,而“中”字则被编码成D6 D0,“国”字被编码成B9 FA,均采用两字节编码。
GBK编码
GBK编码是微软在GBK编码的基础上,进行了一部分拓展,以便支持其他类型的汉字(如繁体、日文汉字、韩文汉字)。“hello中国”在GBK中的编码和GB2312中的编码内容一致,但是GBK不是同一的标准,只是行业的技术规范。
UNICODE编码
由于没有统一起来,各种编码方式层出不穷,各国间的编码方式也很难兼容。因此UNICODE就出现了,它被称为万国码或者统一码。
UNICODE如今已经有了1114112个码位,,被划分成17个平面,每个平面容纳655356个码位。
Unicode 本身只规定了每个字符的数字编号是多少(即码位,或叫做UNICODE值),并没有规定这个编号如何存储,具体怎么存储有多种方式,也就UTF-8、UTF-16、UTF-32.

UTF-32编码
UTF-32采用定长4byte来编码字符,也就是每个字符有4byte长,它是直接将码位转换成4byte数据,这和UTF-8有区别。
使用UTF-32进行存储会有存储空间浪费的问题,比如对于英文使用着来说,要存储“h”这个字符,使用ASCII编码只需要0x68一个byte就可以了,而使用UTF-32却仍需要0x00 0x00 0x00 0x68四个字节,这样就造成了极大的存储空间浪费。
因此UTF-32编码方式虽然简单,直接将码位存储为4byte,但却造成了严重的空间浪费。
UTF-8编码
UTF-8是另一种UNICODE的编码方式,并且相比UTF-32也更节省空间,因此是最常用的Unicode编码方式。
1字节 0xxxxxxx 2字节 110xxxxx 10xxxxxx 3字节 1110xxxx 10xxxxxx 10xxxxxx 4字节 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx 5字节 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 6字节 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 同样以“hello中国”举例,我们来看看它按照UTF-8是怎样保存的。

可以看出,hello这几个字符被存储为68 65 6c 6c 6f,每个字符存储为一个byte,这和ASCII编码方式是一致的。而“中”字被存储为E4 B8 AD,其二进制表示为1110 0100 10111000 10101101。如果吧1110和10这些前置信息去掉,那么我们可以得到其二进制序列为0100111000101101,其十六进制为4E 2D,其就是“中”字的UNICODE值(也就是码位)。
“锟斤拷”的形成
锟斤拷的形成主要是由于编辑者A使用GBK编码保存文本文件后,将此文本文件发送给其他用户B,而用户B按照UTF-8的格式打开并保存后,又将该文件发给了用户C,C重新用GBK编码打开文件就会得到很多很多的”锟斤拷“。下面我们仍然通过例子来说明。

首先是以GBK的编码保存文本。
然后再用UTF-8打开文本并保存,可以看出UTF-8并不能识别以GBK编码保存的“中国”两字,对于UTF-8不能识别的字符,会自动用EF BF BD来替换,也就是对应左边出现的一个问号。

接着,我们将被UTF-8读取了并修改的文件重新按照GBK编码的方式打开。按照GBK编码的方式EF BF被解释成“锟”, BD EF被解释成“斤”, BF BD被解释成“拷”。

烫烫烫和屯屯屯
在Microsoft Visual studio的Debug模式下,用户未初始化的栈内存会被系统初始化为0xcc,而GBK编码中“烫”字的编码正是0xcc 0xcc。而未初始化的堆空间会被初始化成0xcd,而0xcd 0xcd在GBK编码下对应的就是“屯”字。下面我们试着用例子来解释下。

