SLOG
背景
Geo-replicated DBMS
SLOG假设一个数据库系统是跑在横跨世界各地的数据中心的系统,这种系统我们通常称之为Geo-replicated Database Management System(DBMS),它将数据复制多份在各地的资料中心中。
下图展示了一个分布在三个地区的数据库系统。通常一个数据中心会持有一份完整的数据,然后每个数据中心中的数据会再切分成多个不相交的partition。在下图之中,一共有三分备份(replica),然后每个数据中心内有三个partition。数据中心之间会需要时常同步数据来保证数据的一致性。
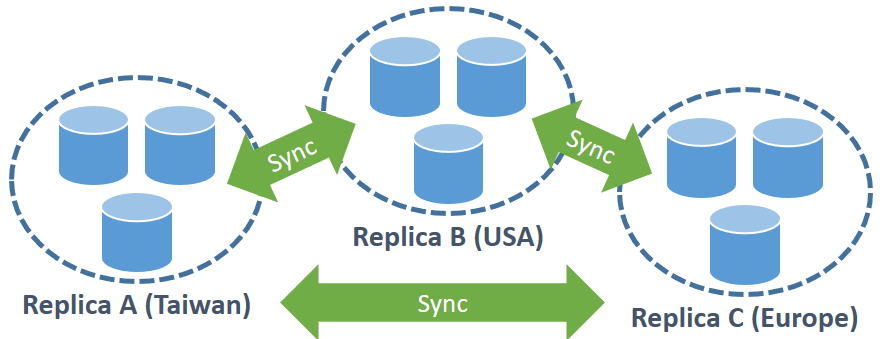
跨区域备份的架构主要有两个目的:
- High Available:因为数据有多个备份,当某个备份无法服务的时候就可以由其他备份提供服务。
- Low Read Latency: 可以优先从地理位置较近的数据中心更快地读取需要的数据。
motivation
分布式数据库系统有三大目标:
- Strict Serializablity
- Low Latency
- High Throughput
到SLOG为止,这时目前尚未有人能够完美同时解决的问题。
例如,要实现strict serializability,通常需要通过协调(coordination)来得到全局的事务顺序,但这会导致write latency较高。如果使用weak consistency(如snapshot isolation)能够同时保证low latency和high throughput,但是又不是strict serializability。
论文发现
SLOG依赖了两个主要发现来达成以上目标:
- 使用者通常都会在同一个地区(数据中心)存取自己的数据
- 并非所有transaction之间都一定要有global order,不冲突的transaction之间的顺序可以排序。
第1点说的就是数据局部性问题,用户的写入和读取大多都在同一个数据中心。
第2点举例来说,如果有两个事务T1、T2,T1修改数据A,T2修改数据B,那么T1、T2谁先谁后都不影响结果。因此这两个transaction无论如何排序,都不影响serializability。
SLOG概念
Home Region
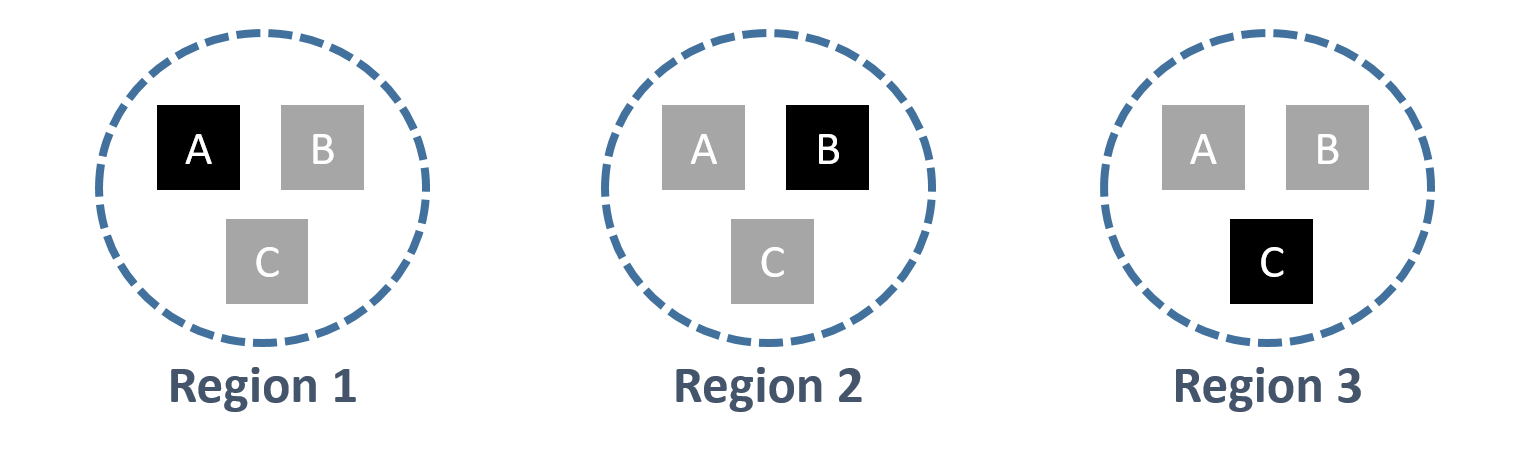
每一组 records 可能会被跨数据中心复制很多份 replica,但是只有一份 replica 是主要的 (primary)。 存放这个主要的 replica 的区域就叫做 home region。 这个时候,一般马上就会想到 master-slave 架构。 那 SLOG 跟那种架构又有什么不同呢? 主要差异是,在常见的 master-slave 架构之中,replica 通常是以整个 database 作为单位,其中 primary replica 一定是整组 database 放在同一个区域中。但是 SLOG 提出的架构是以一组 records 作为单位。也就是说,可能有些 records 的 primary replica 在台湾,有些 records 在美国。 如下图所示,每个方块代表一组 records。 黑色代表 primary。 A 组的 home region 是 region 1,B 组则是在 region 2。
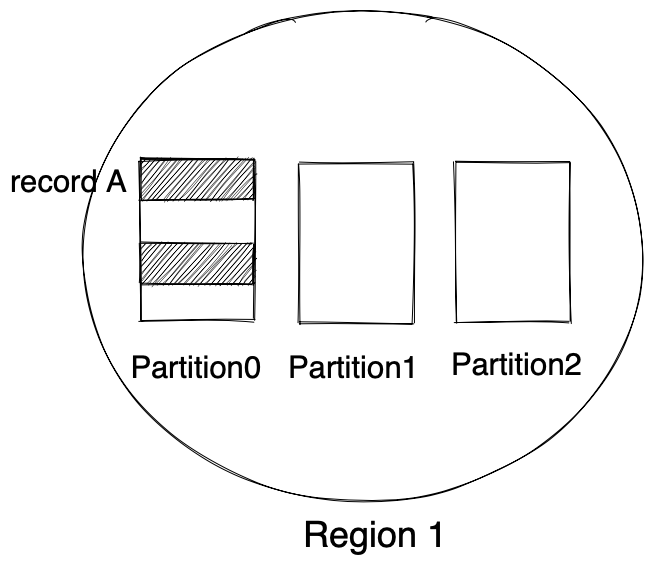
还需要注意的是在一个partition(一个物理机器)中,并不是所有的records都是primary,如下图所示。
那么怎么得到一个record的home-region呢?SLOG在每个region设立一个LookupMaster index,它保存的是record id到record metadata的映射,而record meta由两部分组成,第一部分是该record的当前home-region,第二部分是该record的home-region改变次数(后面有用)。
每个Record中也含有这个metadata,并且当record的metadata被更新的时候,更新LookUpMaster Index。
SLOG将事务分成两类:single-home transaction和multi-home transaction
Single-home Transactions
如果一个事务存取的数据的home region都在同一个region,这种transaction被称作single-home transaction。如下图所示,T1、T2、T3、T4都是single-home transaction。
对于single-home transaction,我们只需要在home region内做冲突处理,其他数据中心的replica只要确保有复制到home region的结果就好。因此SLOG在home region完成transaction之后,就会把log复制到slave。一旦有N个数据中心回复(N由使用者设定),就可以回复client该transaction完成。如此以来,就可以省下跨数据中心的coordination带来的多个round-trip time。
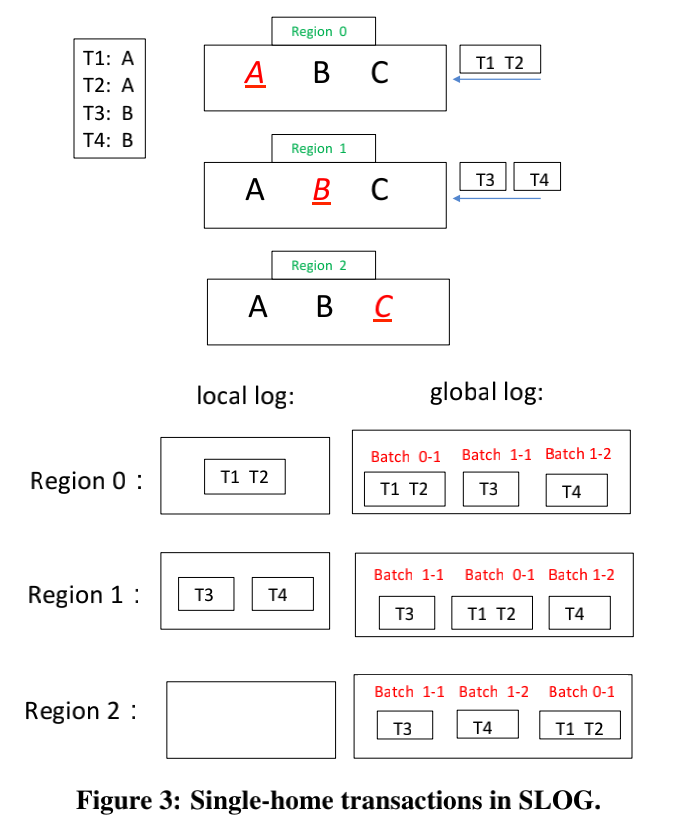
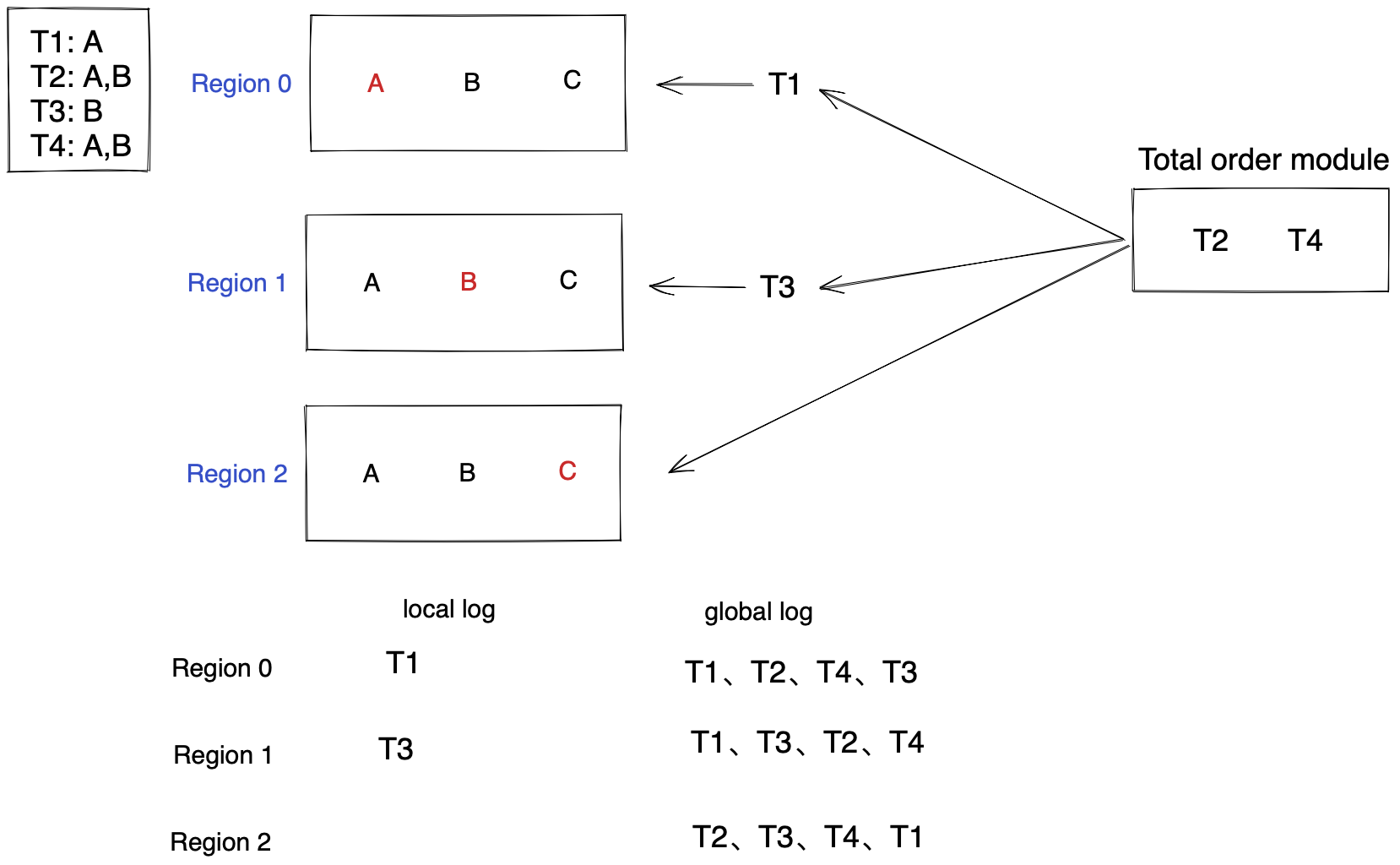
举个例子,T1、T2都只访问数据A,而数据A的home region是region 0,因此T1、T2会在Region0上进行冲突处理(client发送transaction到最近的region,即使被发送到了region1,也会被转发到region 0上)。T3,T4被送到region 1上进行冲突处理。对于single-home类型的transaction,它首先写日志到local log,当local log收集到一批事务日志后,通过paxos发给其他region。global log是全局的事务顺序,它既包含本地local log的日志,也包含从其他region接收到的log,因此每个region的global log顺序可能不一致(但是T1一定在T2之前,T3一定在T4之前)。但是因为它们都是single-home transaction,即使顺序不一致也能保证结果的一致性,因为它们的存取的数据不相交(这也就是论文发现的第2点)。
Batch 0-1 0代表的region id,1代表batch id
global log的顺序确定好之后,region只需要从global log取log然后执行就可以了。
multi-home transactions
如果事务都是single-home的,那就皆大欢喜了,可事实却肯定并非如此。如果一个transaction访问的数据home-region不止一个,那么就称为multi-region transaction。如果figure 3的T2不仅要访问A,还要访问B,那么按照figure 3的方式得到的global log是有问题的,会导致region间数据不一致性。比如region0和region1对数据B最后写入的是T4,而region2最后写入的是T2,导致region0和region2,以及region1和region2的状态不一致。
对于multi-home transaction的处理,我们可以分为multi-home transaction跟multi-home transaction之间的冲突处理,以及multi-home transaction跟single-home transaction之间的冲突处理。
multi-home transaction 跟multi-home transaction之间的冲突处理
SLOG采用deterministic database的概念,在一开始先把所有 multi-home transactions 通过一个 total ordering protocol 进行排序,确定了这些 transaction 的 global order 后,再送到 deterministic execution engine 执行,以确保 consistent 的结果。
如下图,Tx G.1 与 Tx G.2 无论送到哪个 region,都会被强制送进 total ordering layer 进行全域的排序之后,再送到下面的系统开始执行。
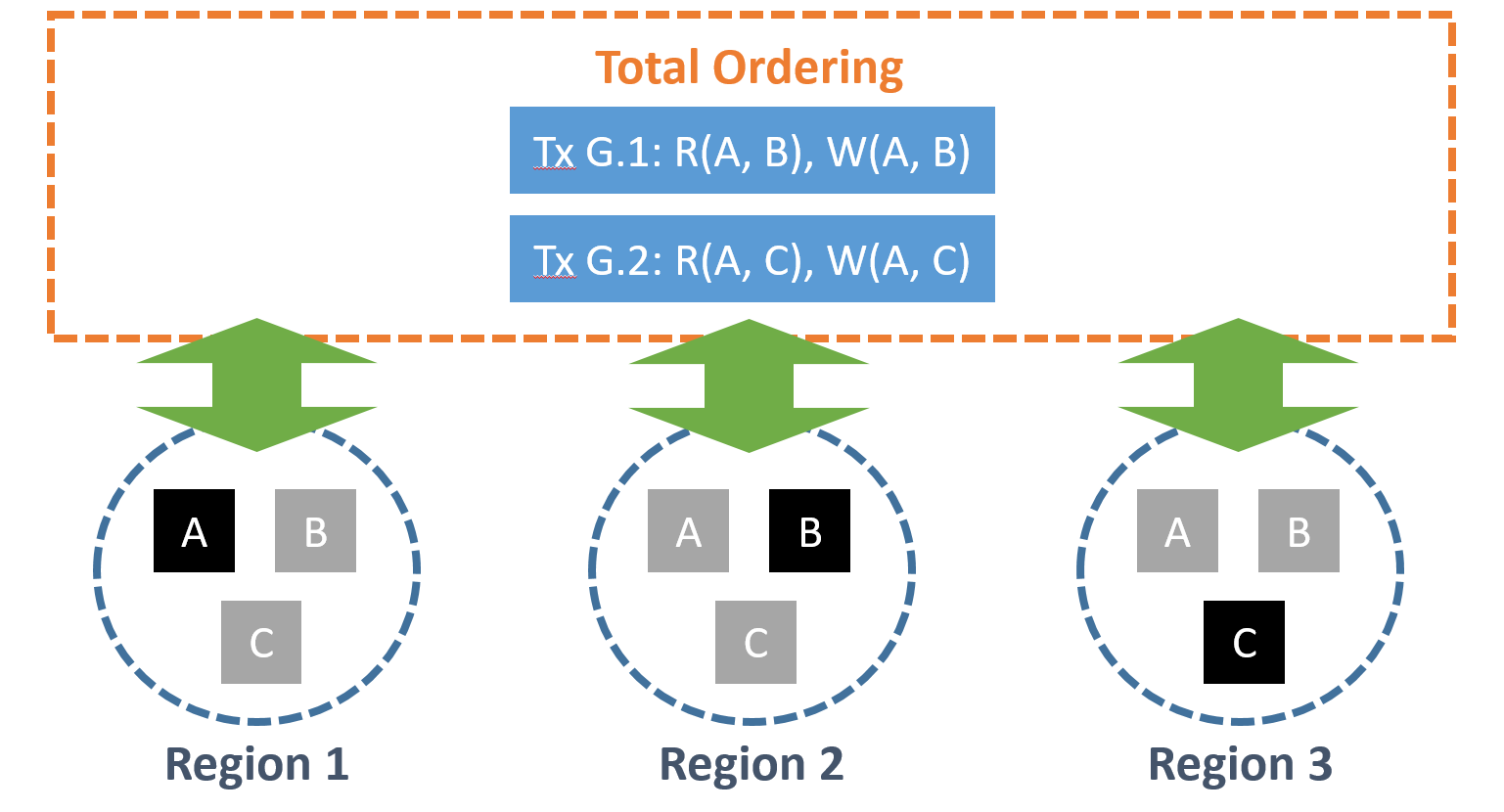
只要保证了事务的全局顺序,那么multi-home transaction和multi-home transaction之间的就完成了并发冲突。
multi-home transaction跟single-home transaction之间的冲突处理
上述的方案能够结果multi-home和multi-home之间的冲突,但是解决不了mutli-home和single-home之间的冲突。
上图中T1和T3是single-home transaction,而T2和T4是multi-home transaction。从上图可以看出multi-home和multi-home transaction间有序(T2在T4前面),但是和single-home transaction间却导致了乱序,这也会导致region间数据不一致性问题。如何解决?加锁。
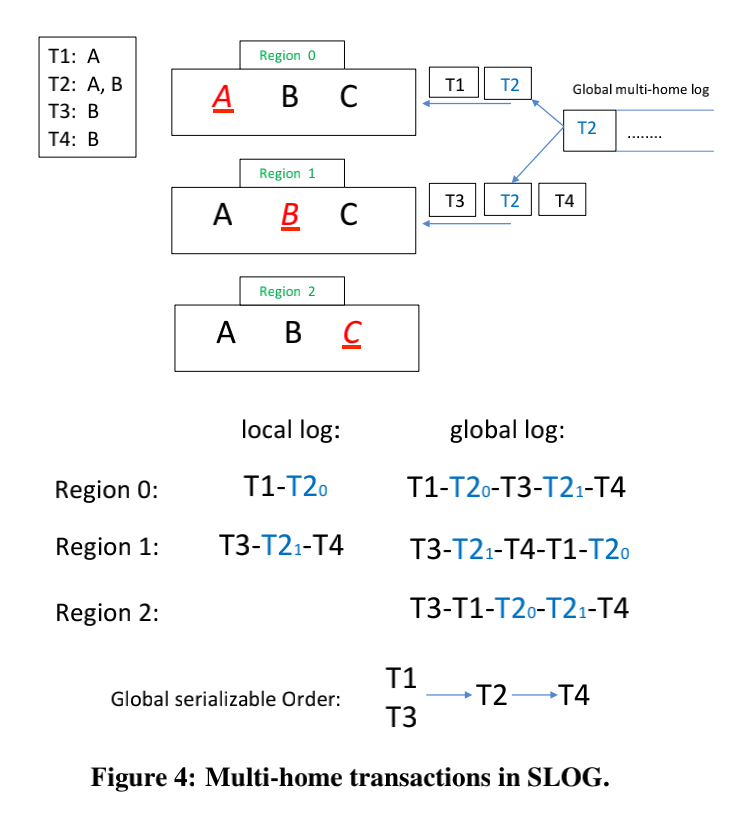
figure4所示,T1、T3、T4为single-home,T2为multi-home transaction。T2在total order module排序出来后,会生成T20和T21两个事务(因为T2涉及两个home region,需要为每一个region都生成一个),这两个事务叫做LockOnlyTxn。T20用来锁住数据项A,T21用来锁住数据项B。single-home transaction对数据读取的时候也需要进行加锁,而multi-home transaction(图中没有画出,我把它称作T2,它出现在global log的任何地方都不影响数据一致性,不相信的话可以举个例子)要执行的时候,必须拿到所有的锁(T20和T21执行)才能够执行,否则会阻塞。
home-region的更换
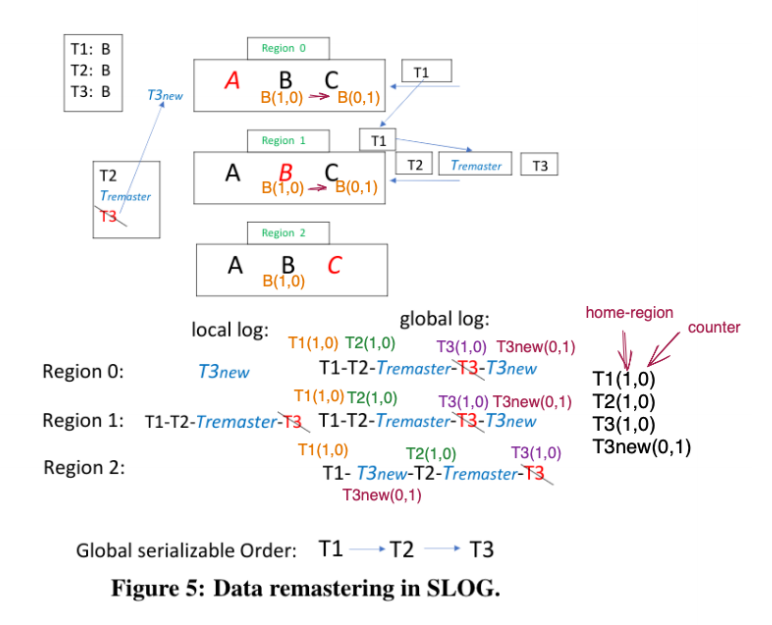
client发送的transaction是发给最近的region,但是此region可能不是home-region,因此这个region会将这个事务发送给home-region。如下图所示。事务T1存取B,它被client发送给了T1,但是T1要访问的数据B的home-region是region1,因此T1被转发给region1.
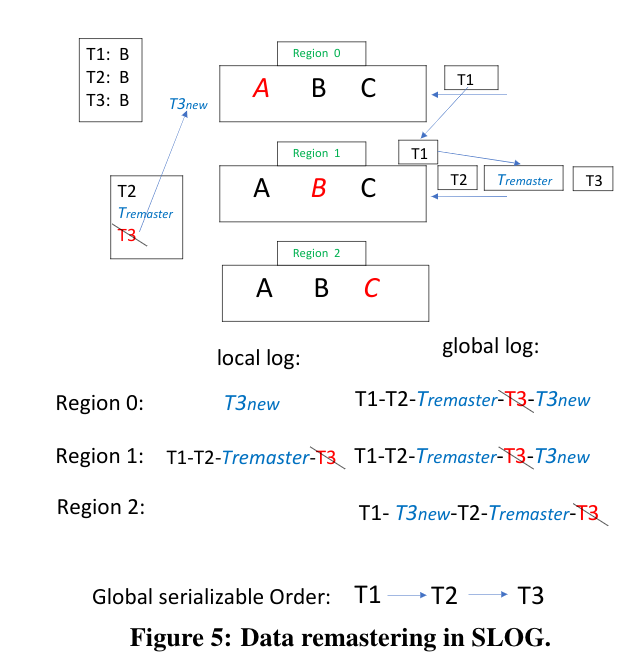
但是这种转发的次数多了肯定影响性能,因此我们希望设定一个阈值(比如region0连着三次都在转发),那么我们希望把B的home-region变更到region0,充分的利用局部性原理(也就是论文发现的第1点),论文把这种行为称为remaster。
但是简单的remaster也会导致region间数据的不一致性。例如在上图中,事务T1、T2、T3都有存取数据B,T1被转发给region1,而Tremaster事务要将数据B的home-region改为region0。当remaster事务执行后,home region改变了,那么T3的home region就不应该在region 1了,而应该是region0,所以T3 abort,并得到T3new,发送给region0。由此得到的global log如图figure 5所示。
那么这么得到的global log就会导致region间的不一致,region0和region1的事务顺序是T1、T2、T3,而region2的事务顺序是T1、T3、T2。
remaster导致的不一致性解决方案
为了解决remaster导致的region间数据不一致性问题,我们通过record的metadata中的counter(也就是该record的home-region被更改了几次)来解决。我们通过举个例子来理解。
当事务T被发送个第一个region时(比如T1发给region0),region0首先通过LookUpMaster查找该record的metadata,并将此metadata信息插入到事务中。因此T1可以表示为T1(1,0),1代表它的当前home region为1,0表示home-region改变了0次。类似的,T2(1,0),T3(1,0),T3new(0,1)。
当我们要对该事务事务涉及的数据项上锁时,会将事务中的数据项counter和region中数据项的metadata中的counter进行比较。如果前者更大,那么说明本region还没有处理remaster请求,因此需要阻塞该事务等到remaster请求被执行后再换行。如果后者更大,那么说明LookupMaster Index中的映射是stale的,本事务应该abort。
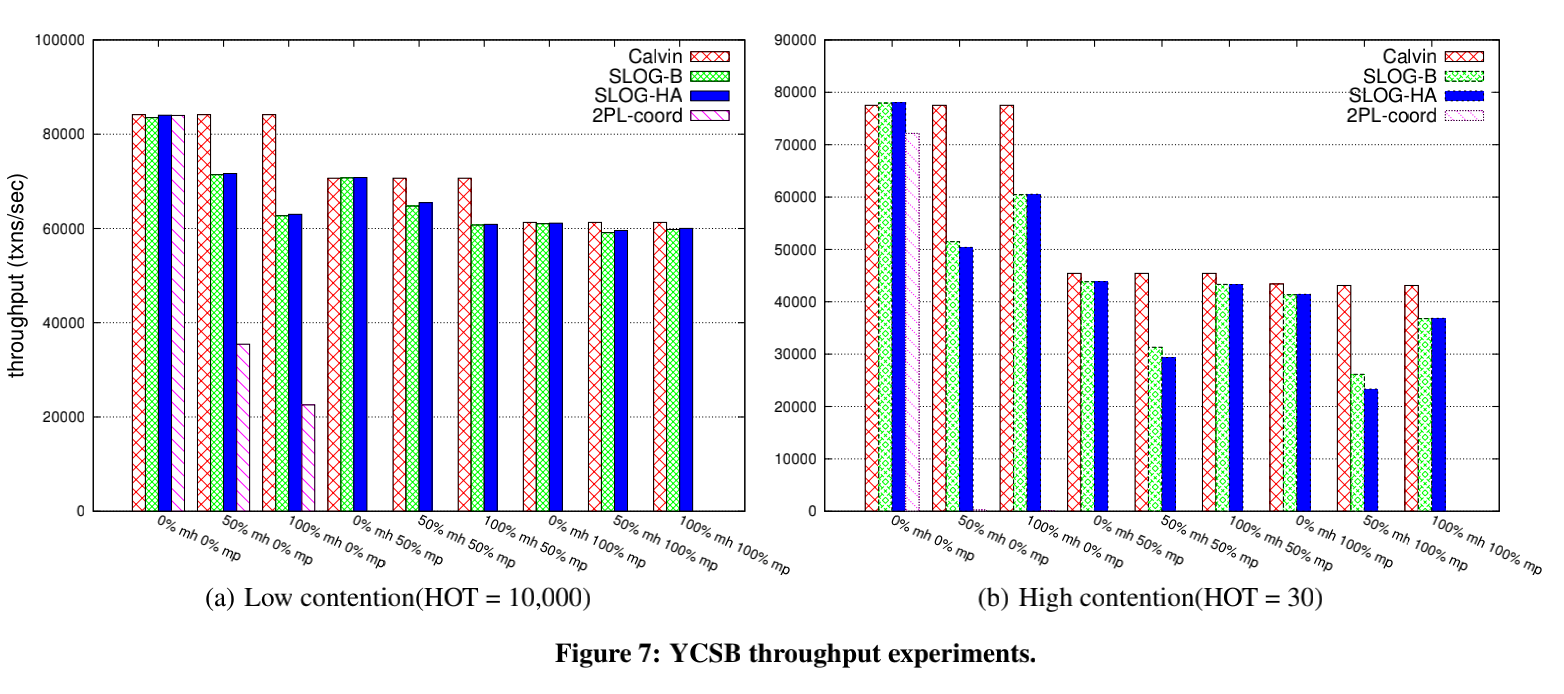
实验结果对比
为什么slog吞吐率低于Calvin?
导致slog吞吐率比calvin低最主要的原因是multi-home事务的存在,在calvin中没有multi-home的概念,因此calvin不受multi-home的影响。
xxxxxxxxxx /client_tcp.c/#include<stdio.h>#include<string.h>#include<stdlib.h>#include<unistd.h>#include<arpa/inet.h>#include<sys/socket.h>int main(){ //创建套接字 int sock = socket(AF_INET, SOCK_STREAM, 0); //服务器的ip为本地,端口号1234 struct sockaddr_in serv_addr; memset(&serv_addr, 0, sizeof(serv_addr)); serv_addr.sin_family = AF_INET; inet_pton(AF_INET, "127.0.0.1", &serv_addr.sin_addr); serv_addr.sin_port = htons(1234); //向服务器发送连接请求 connect(sock, (struct sockaddr*)&serv_addr, sizeof(serv_addr)); //发送并接收数据 char buffer[40]; printf("Please write:"); scanf("%s", buffer); write(sock, buffer, sizeof(buffer)); memset(buffer, 0, sizeof(buffer)); read(sock, buffer, sizeof(buffer) - 1); printf("Serve send: %s", buffer); //断开连接 close(sock); return 0;}c
但是当multi-partition(跨分片)事务数量变多的时候,calvin和slog的吞吐率差距会变小,因为calvin对于跨分片的事务也需要进行协调带来额外的开销,而slog在处理multi-home的时候顺带也解决了(部分)multi-partition的冲突。
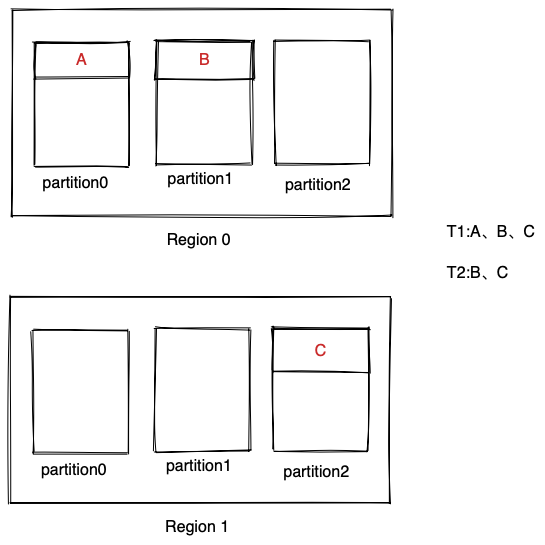
如下图所示,T1和T2既是multi-home transaction又是multi-partition事务,calvin对于multi-partion事务需要做coordination,而slog需要对multi-home事务做coordination,因此当multi-partition的比例较高时,slog和calvin的差距就不是很明显。
为什么slog延迟比calvin低?
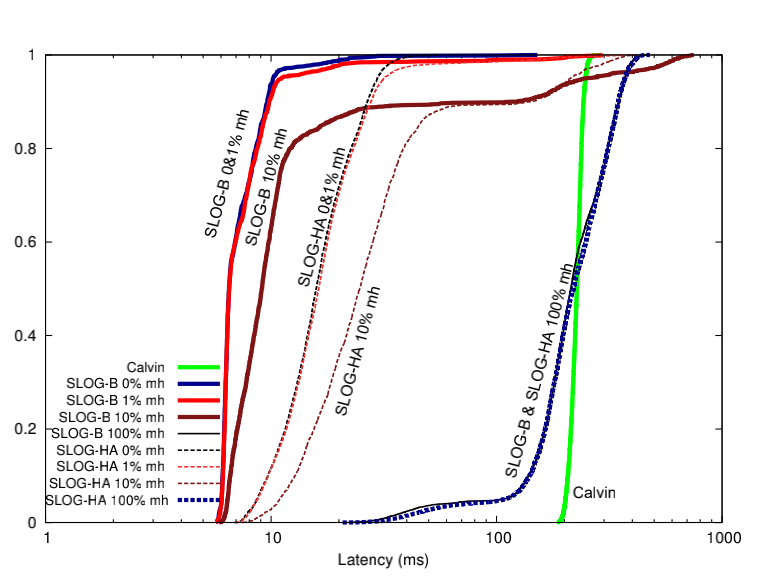
上图曲线越靠近左边代表延迟越低。可以看出slog延迟在multi-home比例很低(也就是single-home transaction比例很高)的时候明显优于calvin。因为对于slog来说,single-home transaction每个record有它的master,只要transaction的日志写入到master(home-region)上该事务就可以返回了,然后异步地使用paxos同步日志给slave region,因此延迟比较低。而multi-home事务越多,对slog的latency影响越大。
参考文献
- https://www.slmt.tw/blog/2019/10/20/paper-slog/
- Thomson, Alexander, and Daniel J. Abadi. “The case for determinism in database systems.” Proceedings of the VLDB Endowment 3.1-2 (2010): 70-80.