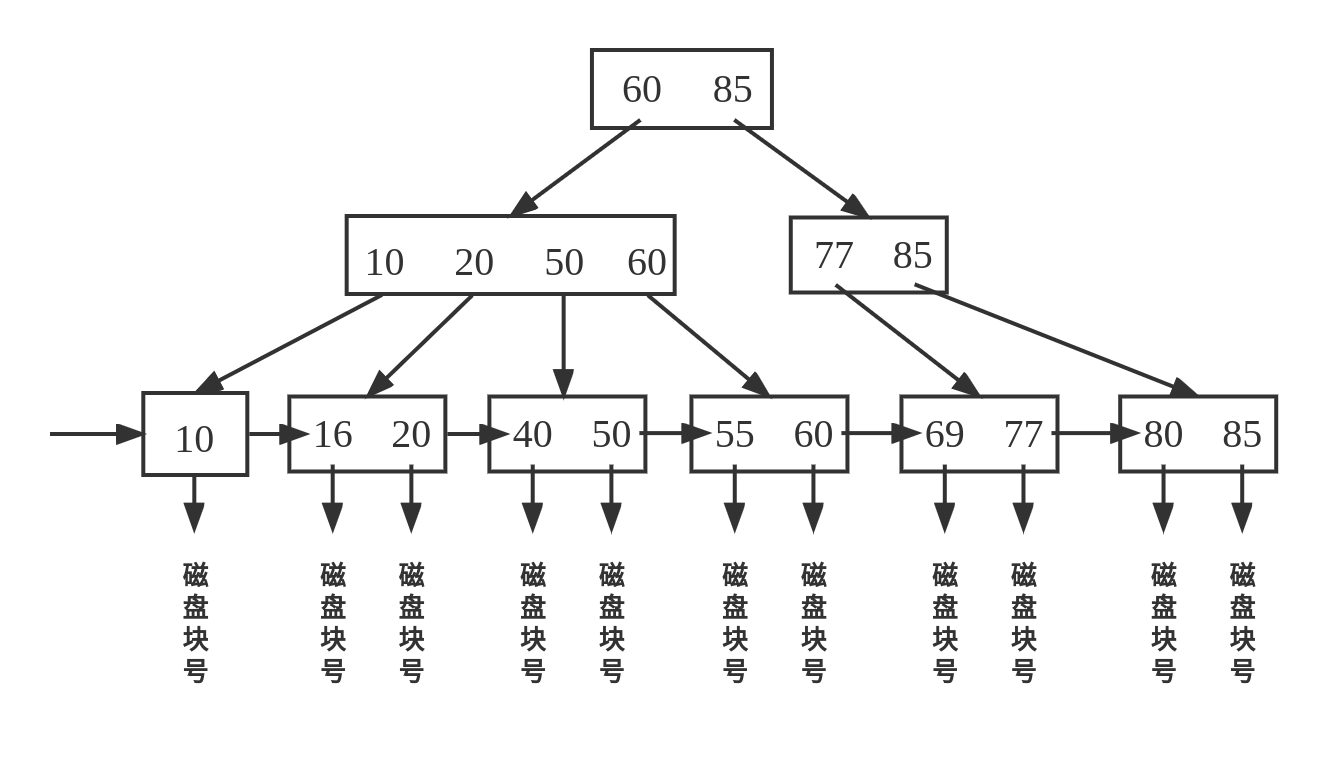
B-Tree
本文内容参考自YouTube Abdul Bari,若有错误还请指正。十分推荐观看原视频,讲得非常清晰易懂。
前言
本文将从硬盘的物理结构说起,介绍关系表中的数据如何在磁盘上进行存储和表示。并通过查询的例子,说明为什么要使用索引来加快查询。本文将从索引结构的设计角度,从m路查找树过渡到B树和B+树。
磁盘结构
一块硬盘由多个磁盘片组成,每个磁盘片像一张CD光盘一样。和CD光盘不同的是,每个磁盘片都有两面,且每一面都能够存储数据,每一面均有一个读写头去读写数据。下图为由4个磁盘片和8个读写头组成的硬盘。
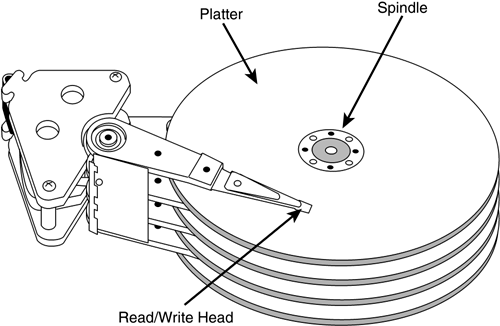
对于磁盘片的每一面,都会被划分成若干个同心圆,他们被称为磁道。而每一个磁道,又会被划分成多个扇区,每个扇区的大小通常为512B。下图为盘面的示意图,由图可知,一个盘面由4个磁道组成,而每一个磁道由7个扇区构成,每个扇区大小通常为512B。

因此,如果我们知道了数据的盘面号、磁道号、扇区号,我们就能够准确定位数据所在扇区,并且能将该扇区512B的数据从磁盘读取到内存中。这种通过盘面号、磁道号、扇区号定位数据的方式称为CHS寻址。磁盘除了CHS寻址外,还有另一种寻址方式:LBA寻址。也就是说,你只需要告诉我你需要的扇区号,磁盘适配器便能从磁盘中读取所需的扇区。这种方式比CHS寻址更简洁更直观,因此本文采用扇区号的方式来代指磁盘块号。
表数据如何存储在磁盘上
假设我们要存储关系表Employee的数据,其结构如下:
1 | CREATE TABLE Empoyee( |
由此可知,id占用10字节,name占用50字节,department占用8字节,info占用50字节。则每插入一行数据会占用128字节的空间
下面是要进行存储的表数据,一共有100行数据要进行存储:
| id | name | department | phone | info |
|---|---|---|---|---|
| 1 | John | 12345678 | this guy is so nice | |
| 2 | Tom | 12352135 | good | |
| 3 | Anid | ... | ... | ... |
| 4 | Khan | ... | ... | ... |
| ... | ... | ... | ... | ... |
由前文我们知道,一个磁盘块(即一个扇区)的大小为512字节,一行表数据会占用128字节,那么一个磁盘块能够存放4行表数据。那么对于100行表数据,我们需要25个磁盘块进行存储。

如果我们要进行SELECT * FROM Employee WHERE id = 99查询,由于没有索引信息,因此需要将磁盘块依次读入内存中,查找该磁盘块中是否含有该数据行,在最坏的情况下需要读取25个磁盘块。如果给id加上索引信息又会如何呢?
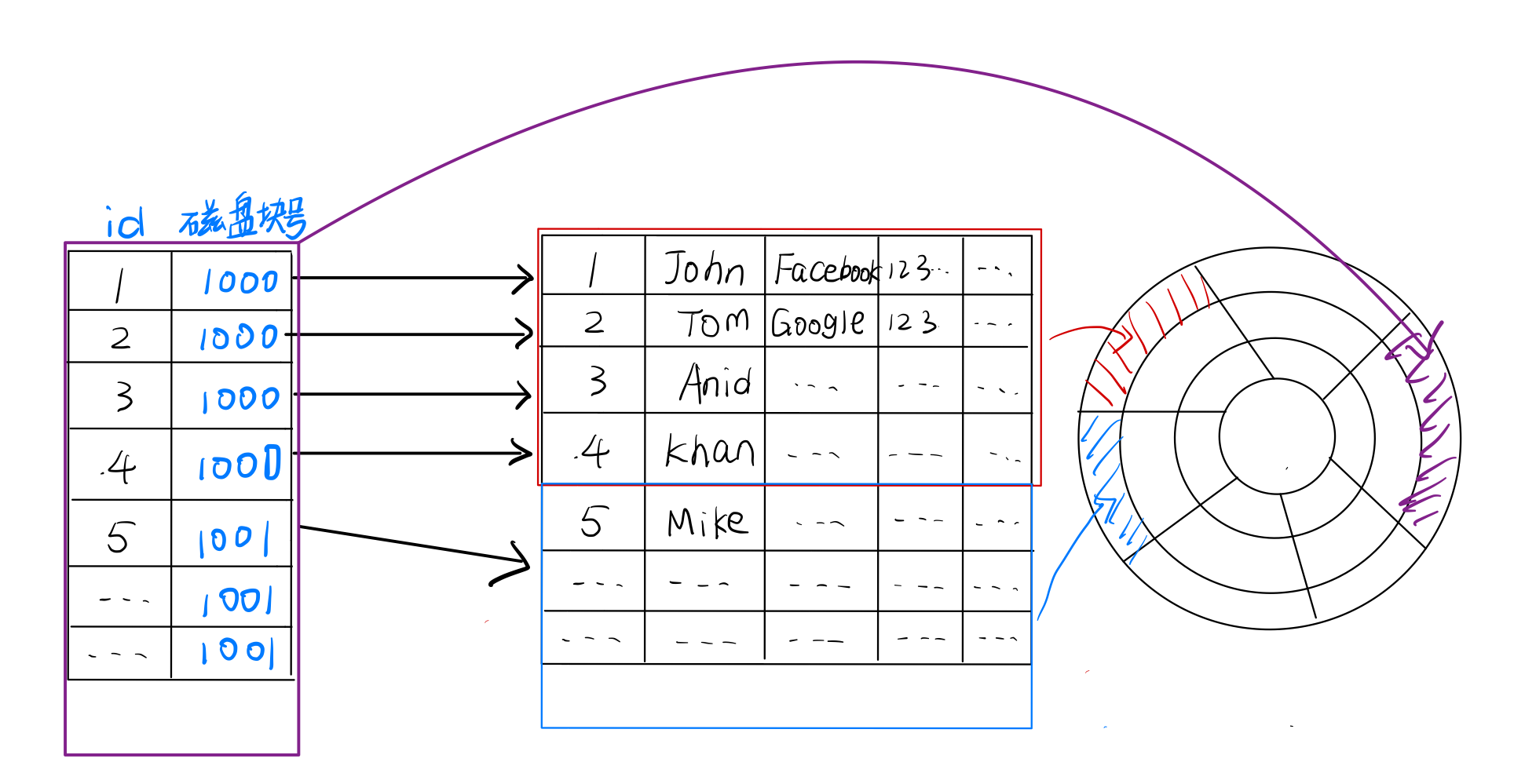
我们现在给id加上索引信息,通过id就能够知道该行表数据在哪一个磁盘块上。假设id占10字节,磁盘块号占6字节,则一行索引信息占用16字节,一个512字节大小磁盘块能够容纳32行索引信息。那么100行表数据,100/32则至少需要4个额外的磁盘块来存储索引信息。当对id加上索引信息后,我们只需要将4个索引磁盘块读入内存中然后将id与99进行比对,就能够找到对应的磁盘块号,再将数据磁盘块后读入内存就完成了数据的查找。因此,id含有索引信息后共需要读入4+1=5个磁盘块。
现在,如果我们要存储的数据行有1000行,那么需要250个数据块存储表数据,需要40个磁盘块存储索引信息。这就意味着我们又需要读取40个索引磁盘块进行查找了。那么该如何进行优化呢?与页表类似,我们可以对索引表再创建一个索引表。下图展示了该的过程。
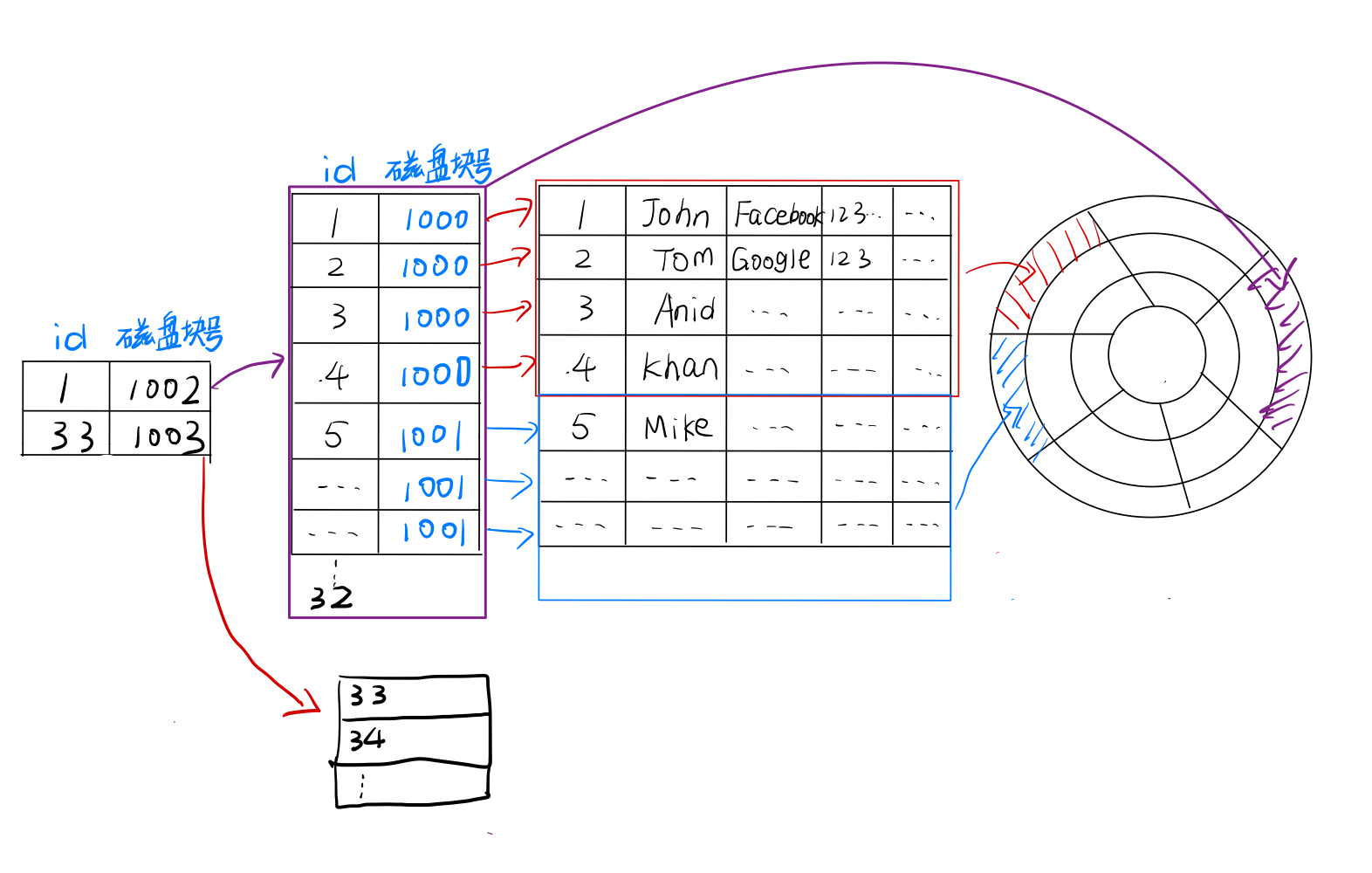
对于40个索引磁盘块,我们只需要40/32=2个二级索引磁盘块来存储二级索引信息。当对1000行数据进行SELECT * FROM Employee WHERE id = 18;时,首要必须先读取二级索引磁盘块,它记载了某个id区间的行数据在哪个磁盘块。由于18大于1小于33,因此它的索引数据应该在1002号磁盘块。接着我们读取1002号磁盘块进入内存,通过比对id找到id=18数据行所指向的磁盘块,假设其磁盘块号为1220,那么我们只需要将1220号磁盘块读入内存就完成了数据的查找。我们一个读取了二级索引磁盘块1块、一级索引磁盘块一块、数据磁盘块一块,一共只读取了三块磁盘块。
若将该多级索引结构向右旋转,便得到了一颗树的结构,我们希望在插入数据的时候,树的结构能够自动地合并、分裂维持索引信息的正确性,这便是B树和B+树的由来。
m路查找树
在介绍B树和B+树之前,我们先来了解二分查找树和m路查找树。
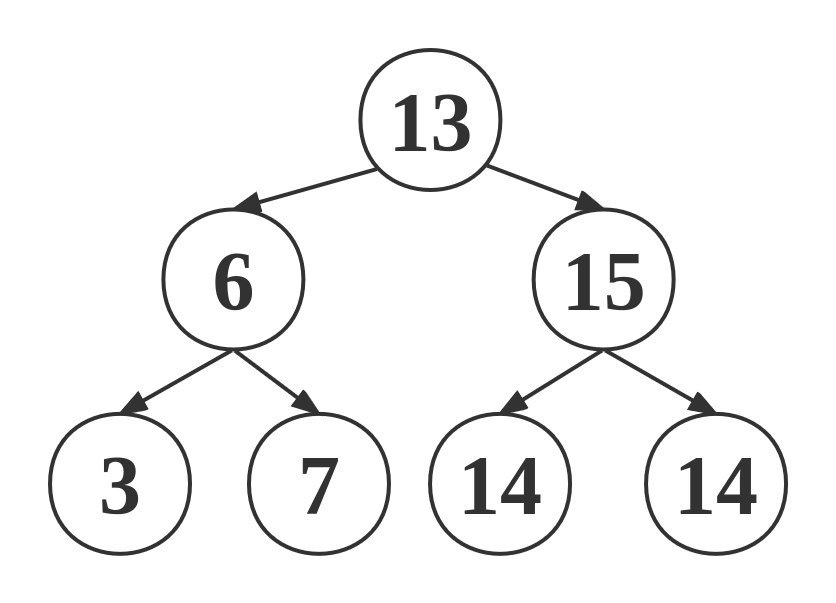
上述图片描述了一棵二分查找树(Binary Search Tree, BST)。加入我们要查找14,那么先和根节点进行比较,如果小于根节点向左子树查找,大于根节点向右子树查找。14>13,因此向右查找。接着14<15,向左子树查找。最终我们找到了需要的值14。
而m路查找树就是每个节点可以有m个孩子节点,下图是一棵三路查找树。
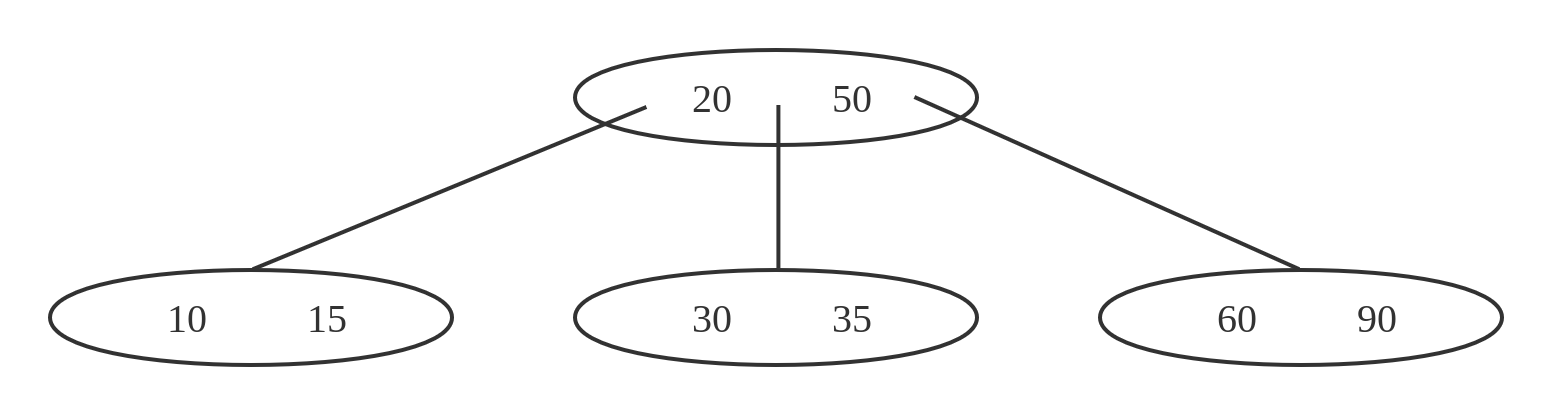
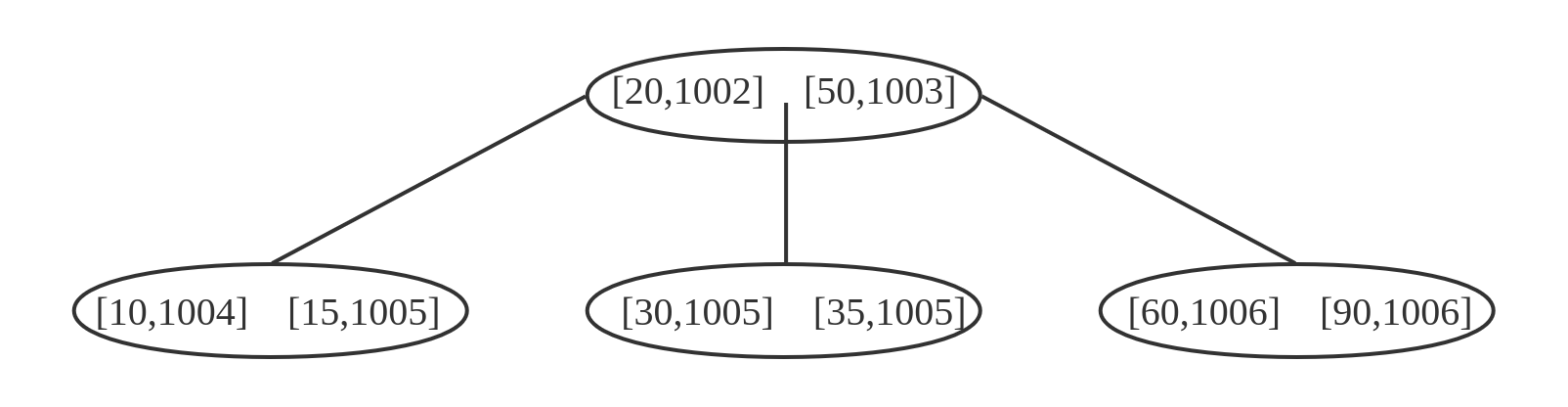
通过查找树,我们通常能在O(logn)的时间复杂度下找到我们需要的值。那么,这些查找树是如何与数据库中的索引对于起来的呢?一般来说,树的每个节点便对应一个磁盘块。每个节点中除了存储Key值外,也会存储Value的信息,也就是磁盘块号。当我们通过m路查询树找到了id的时候,我们也就找到了对应的磁盘块号。下图是示意图。
但是m路查找树存在着问题。假如我们要插入Key:10、20、30.如果不加任何限制和约束,它会变成下图所示的结构。
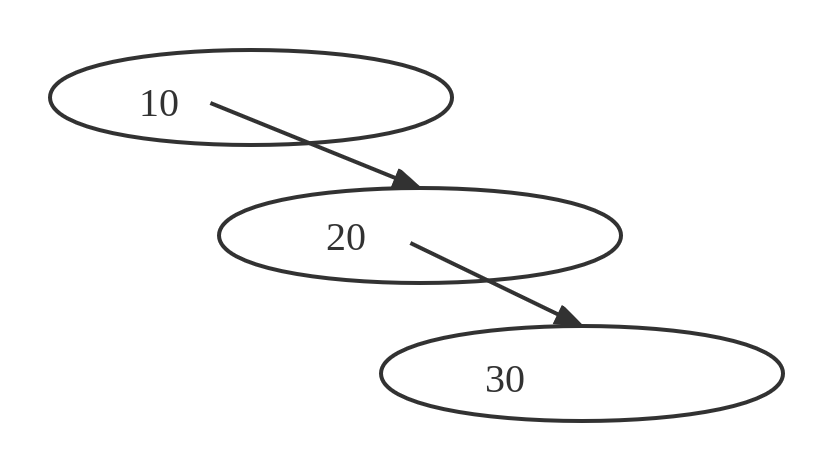
可以看出,没有限制和约束,m路查找树退化成了线性查找,时间复杂度为O(log(n))。为了解决这一问题,人们便提出B树,可以说,B树就是m路查找树加上相应的规则。
B树
要使m路查找树成为m阶B树,需要满足以下条件:
- 非根节点必须至少有\(\lceil \frac{m}{2}\rceil\)个孩子节点
- 根节点可以只有2个孩子节点
- 叶子节点在同一层
- 自底向上构建树
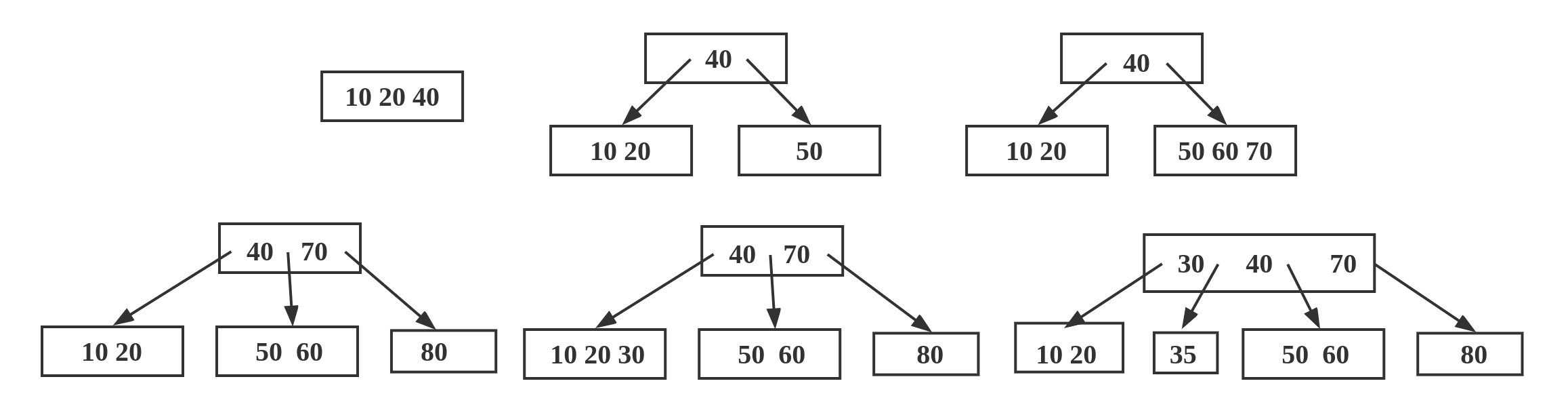
这里通过例子来说明这些规则。假如我们要插入的Key序列为10,20,40,50,60,70,80,30,35那么我们构建的4阶B树过程如下图所示。
B+树
B+树和B树区别不大,最主要的区别有如下两点:
- B+树非叶子节点并不存储Value,而只存Key。要找到磁盘块信息必须找到叶子节点位置。这样做可以增加每个磁盘块容纳Key的数量,也能降低树的高度,减少IO的次数。
- 叶子节点含有所有的Key,非叶子节点的Key也会复制一份到叶子结点中。并且通过链表的形式将叶子节点组织在一起。