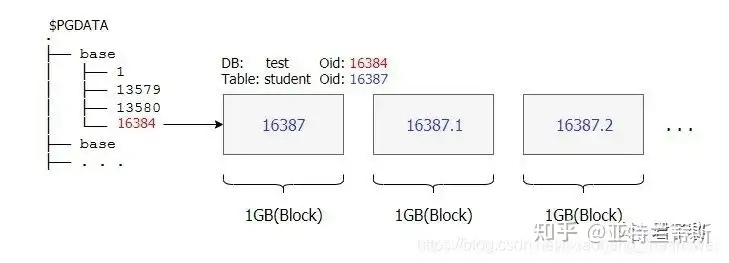
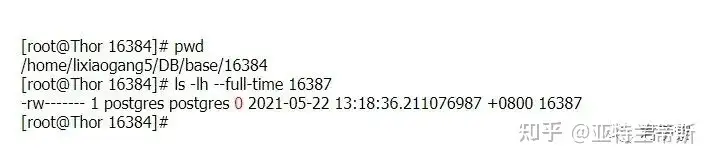
在研究表文件之前,我们先要知道postgres的数据蔟目录位置。因为所有的数据库、表、索引、配置文件等等都是存储在数据蔟目录下的,即PGDATA。如果你不确定当前环境上面PostgreSQL的数据蔟目录位置,没关系,你仅需要psql登录终端,然后执行
SHOW DATA_DIRECTORY;命令即可得到。如下图所示,当前环境的数据蔟目录是:/home/singheart/data。
1 2 3 4 5 6 7 8
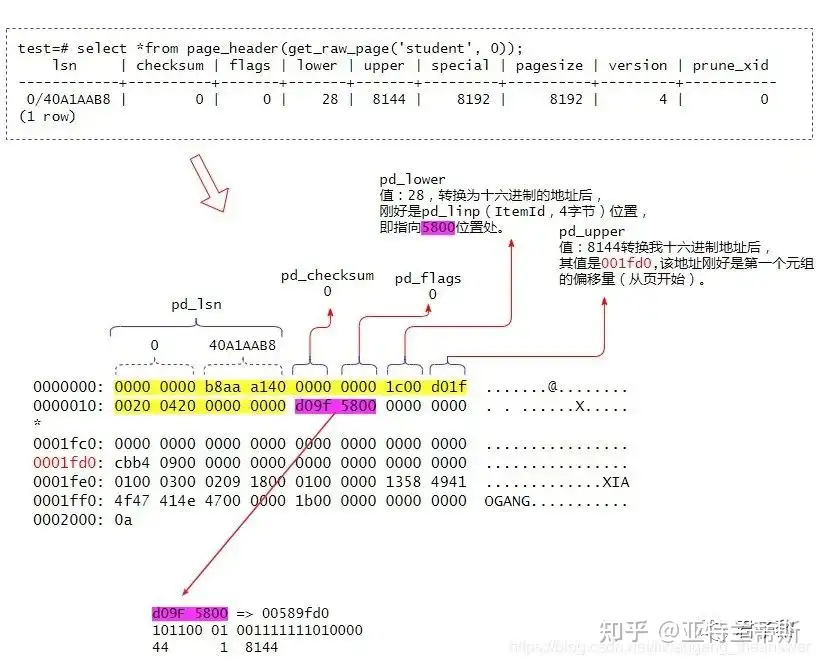
test=# test=# SHOW DATA_DIRECTORY; data_directory ---------------------- /home/singheart/data (1 row)
postgres=# CREATE DATABASE test; CREATE DATABASE test=# test=# CREATE TABLE student(id SERIAL PRIMARY KEY, name VARCHAR, age INT NOT NULL); CREATE TABLE
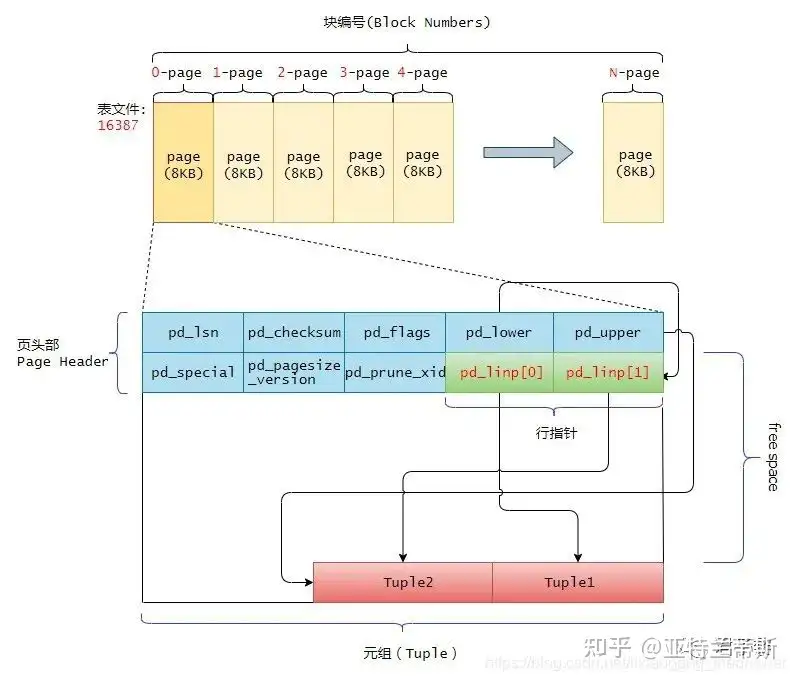
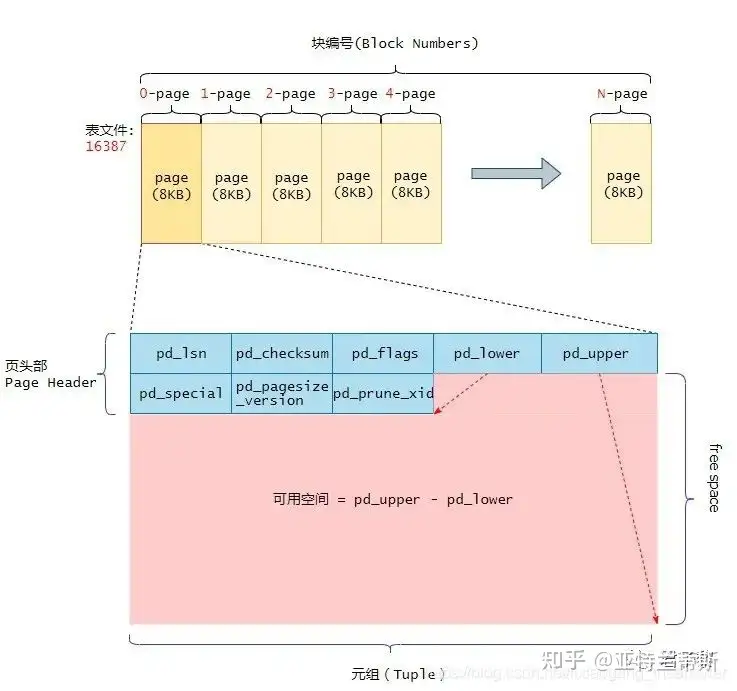
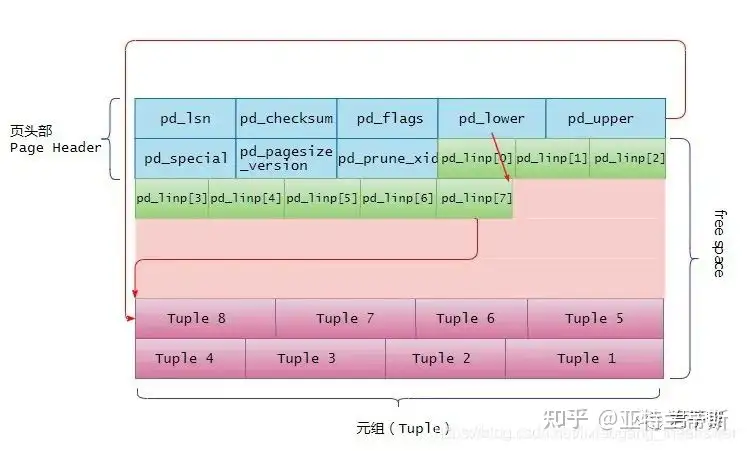
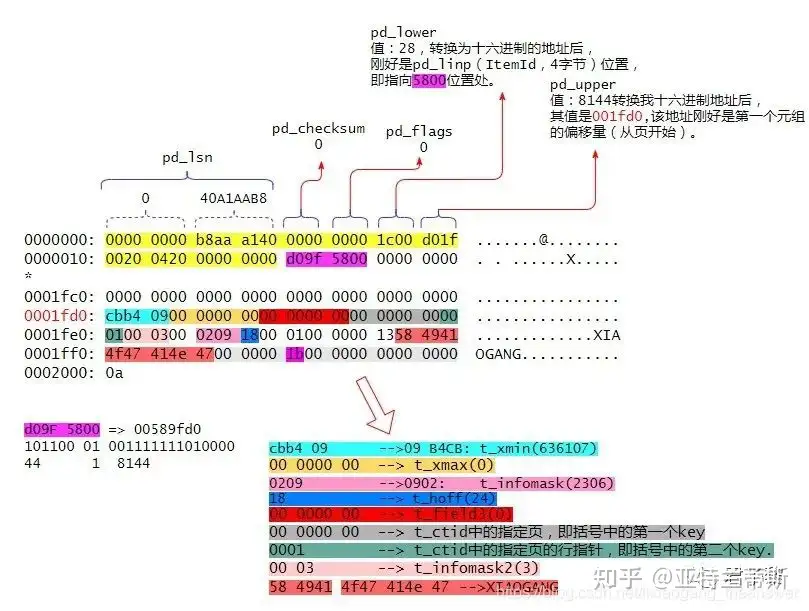
typedefstructPageHeaderData { /* XXX LSN is member of *any* block, not only page-organized ones */ PageXLogRecPtr pd_lsn; /* LSN: next byte after last byte of xlog * record for last change to this page */ uint16 pd_checksum; /* checksum */ uint16 pd_flags; /* flag bits, see below */ LocationIndex pd_lower; /* offset to start of free space */ LocationIndex pd_upper; /* offset to end of free space */ LocationIndex pd_special; /* offset to start of special space */ uint16 pd_pagesize_version; TransactionId pd_prune_xid; /* oldest prunable XID, or zero if none */ ItemIdData pd_linp[FLEXIBLE_ARRAY_MEMBER]; /* line pointer array [行指针数组]*/ } PageHeaderData;
pd_linp是极为重要的成员变量,它是一个零长度数组(Arrays of Length Zero)。当页中没有插入数据时候,它的数组元素个数是0,因此这个pd_linp也就是上图中所谓的“行指针”数组。它指向该页中的元组(也就是表记录)。其pd_linp的数据类型是:
1 2 3 4 5 6
typedefstructItemIdData { unsigned lp_off:15, /* offset to tuple (from start of page) */ lp_flags:2, /* state of line pointer, see below */ lp_len:15; /* byte length of tuple */ } ItemIdData;
typedefstructItemIdData { unsigned lp_off : 15, /* offset to tuple (from start of page) */ lp_flags : 2, /* state of item pointer, see below */ lp_len : 15; /* byte length of tuple */ } ItemIdData; typedefstructPageHeaderData { /* XXX LSN is member of *any* block, not only page-organized ones */ PageXLogRecPtr pd_lsn; /* LSN: next byte after last byte of xlog * record for last change to this page */ uint16 pd_checksum; /* checksum or timelineId */ uint16 pd_flags; /* flag bits, see below */ LocationIndex pd_lower; /* offset to start of free space */ LocationIndex pd_upper; /* offset to end of free space */ LocationIndex pd_special; /* offset to start of special space */ uint16 pd_pagesize_version; ShortTransactionId pd_prune_xid; /* oldest prunable XID, or zero if none */ ItemIdData pd_linp[FLEXIBLE_ARRAY_MEMBER]; /* line pointer array [行指针数组]*/ } PageHeaderData;
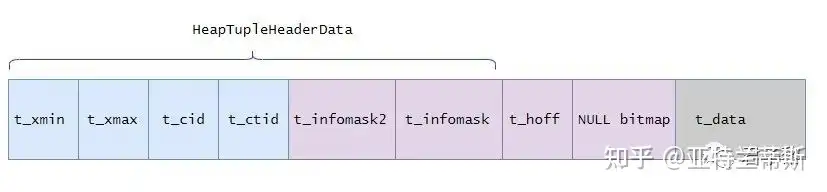
// tuple的相关定义 typedefstructHeapTupleFields { ShortTransactionId t_xmin; /* inserting xact ID */ ShortTransactionId t_xmax; /* deleting or locking xact ID */
union { CommandId t_cid; /* inserting or deleting command ID, or both */ ShortTransactionId t_xvac; /* old-style VACUUM FULL xact ID */ } t_field3; } HeapTupleFields;
typedefstructDatumTupleFields { int32 datum_len_; /* varlena header (do not touch directly!) */
int32 datum_typmod; /* -1, or identifier of a record type */
Oid datum_typeid; /* composite type OID, or RECORDOID */
/* * Note: field ordering is chosen with thought that Oid might someday * widen to 64 bits. */ } DatumTupleFields;
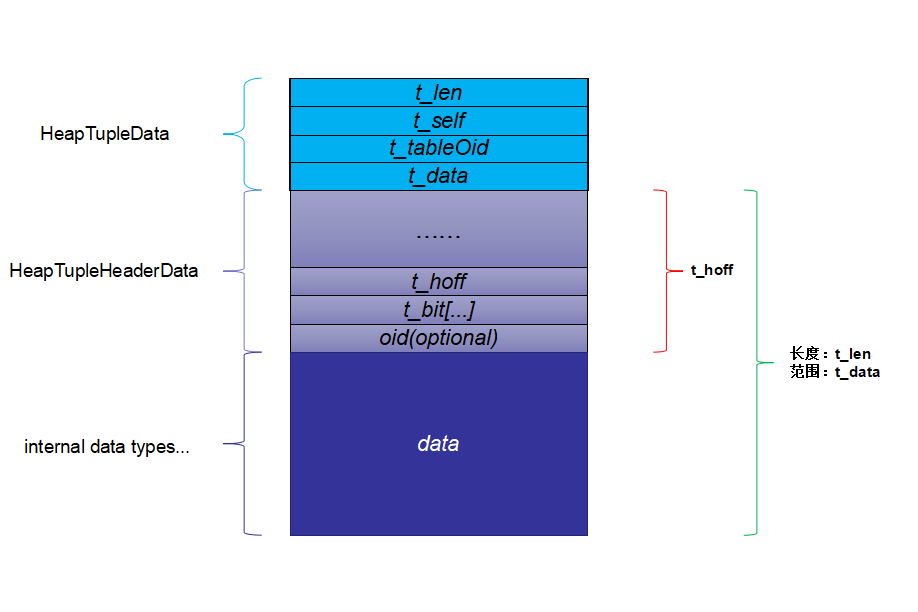
structHeapTupleHeaderData { union { HeapTupleFields t_heap; DatumTupleFields t_datum; } t_choice;
ItemPointerData t_ctid; /* current TID of this or newer tuple (or a * speculative insertion token) */ /* Fields below here must match MinimalTupleData! */ #define FIELDNO_HEAPTUPLEHEADERDATA_INFOMASK2 2 uint16 t_infomask2; /* number of attributes + various flags */
#define FIELDNO_HEAPTUPLEHEADERDATA_INFOMASK 3 uint16 t_infomask; /* various flag bits, see below */
typedefstructItemIdData { unsigned lp_off:15, /* offset to tuple (from start of page) */ lp_flags:2, /* state of line pointer, see below */ lp_len:15; /* byte length of tuple */ } ItemIdData;
structHeapTupleHeaderData { union { HeapTupleFields t_heap; DatumTupleFields t_datum; } t_choice;
ItemPointerData t_ctid; /* current TID of this or newer tuple (or a * speculative insertion token) */ /* Fields below here must match MinimalTupleData! */ #define FIELDNO_HEAPTUPLEHEADERDATA_INFOMASK2 2 uint16 t_infomask2; /* number of attributes + various flags */
#define FIELDNO_HEAPTUPLEHEADERDATA_INFOMASK 3 uint16 t_infomask; /* various flag bits, see below */
typedefstructHeapTupleFields { TransactionId t_xmin; /* inserting xact ID */ TransactionId t_xmax; /* deleting or locking xact ID */
union { CommandId t_cid; /* inserting or deleting command ID, or both */ TransactionId t_xvac; /* old-style VACUUM FULL xact ID */ } t_field3; } HeapTupleFields;
/* * information stored in t_infomask: */ #define HEAP_HASNULL 0x0001 /* has null attribute(s) */ #define HEAP_HASVARWIDTH 0x0002 /* has variable-width attribute(s) */ #define HEAP_HASEXTERNAL 0x0004 /* has external stored attribute(s) */ #define HEAP_HASOID_OLD 0x0008 /* has an object-id field */ #define HEAP_XMAX_KEYSHR_LOCK 0x0010 /* xmax is a key-shared locker */ #define HEAP_COMBOCID 0x0020 /* t_cid is a combo cid */ #define HEAP_XMAX_EXCL_LOCK 0x0040 /* xmax is exclusive locker */ #define HEAP_XMAX_LOCK_ONLY 0x0080 /* xmax, if valid, is only a locker */
/* xmax is a shared locker */ #define HEAP_XMAX_SHR_LOCK (HEAP_XMAX_EXCL_LOCK | HEAP_XMAX_KEYSHR_LOCK)
#define HEAP_LOCK_MASK (HEAP_XMAX_SHR_LOCK | HEAP_XMAX_EXCL_LOCK | \ HEAP_XMAX_KEYSHR_LOCK) #define HEAP_XMIN_COMMITTED 0x0100 /* t_xmin committed */ #define HEAP_XMIN_INVALID 0x0200 /* t_xmin invalid/aborted */ #define HEAP_XMIN_FROZEN (HEAP_XMIN_COMMITTED|HEAP_XMIN_INVALID) #define HEAP_XMAX_COMMITTED 0x0400 /* t_xmax committed */ #define HEAP_XMAX_INVALID 0x0800 /* t_xmax invalid/aborted */ #define HEAP_XMAX_IS_MULTI 0x1000 /* t_xmax is a MultiXactId */ #define HEAP_UPDATED 0x2000 /* this is UPDATEd version of row */ #define HEAP_MOVED_OFF 0x4000 /* moved to another place by pre-9.0 * VACUUM FULL; kept for binary * upgrade support */ #define HEAP_MOVED_IN 0x8000 /* moved from another place by pre-9.0 * VACUUM FULL; kept for binary * upgrade support */ #define HEAP_MOVED (HEAP_MOVED_OFF | HEAP_MOVED_IN)
typedefstructItemIdData { unsigned lp_off:15, /* offset to tuple (from start of page) */ lp_flags:2, /* state of line pointer, see below */ lp_len:15; /* byte length of tuple */ } ItemIdData;