condition-variable
前面已经对mutex以及相关的lock进行了梳理,这里对thread和condition_variable做一个简单的梳理。
# std::thread
通过该函数能够创建一个线程。
1 |
|
前面已经对mutex以及相关的lock进行了梳理,这里对thread和condition_variable做一个简单的梳理。
通过该函数能够创建一个线程。
1 |
|
参考https://baijiahao.baidu.com/s?id=1653384309305389312&wfr=spider&for=pc
我们知道在C++中char占用一个字节,int占用四个字节。那么类在内存中是怎么布局的呢?成员变量和成员函数是放在一起存储的吗?
笔者踩了许多坑,最大的两个问题是Riak必须配置3个节点,第二个问题是得手动修改jar包才能进行配置。至于用Python和Java连接Riak,笔者有时间会单独出一篇教程。
CentOS 7.6 64位
若未有特殊说明,所有操作均在root下进行操作。
Fail-stop failure(i.e. machine crashes, os kernel panic), not including software or hardware bugs.
本文内容参考自YouTube Abdul Bari,若有错误还请指正。十分推荐观看原视频,讲得非常清晰易懂。
本文将从硬盘的物理结构说起,介绍关系表中的数据如何在磁盘上进行存储和表示。并通过查询的例子,说明为什么要使用索引来加快查询。本文将从索引结构的设计角度,从m路查找树过渡到B树和B+树。
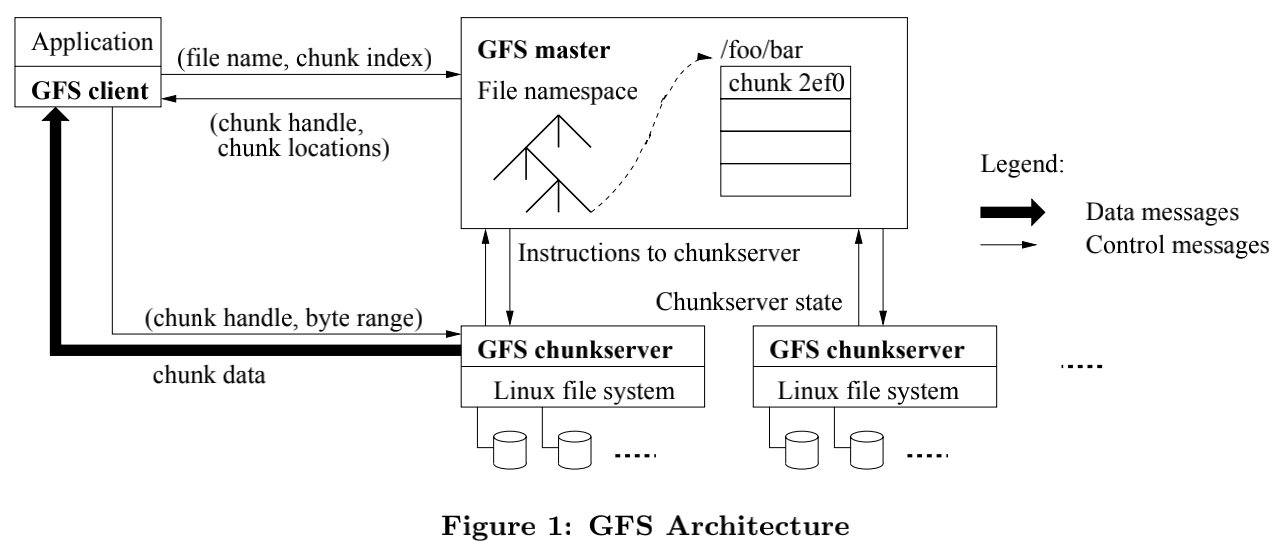
在GFS中,一个文件由多个chunk组成,每一个chunk大小都是64MB,而一个文件的chunk可能不在同一个chunkserver上,也就是分布在不同的chunkserver上。
GFS采用的是单主架构,client通过filename和offset向master索要chunk信息,master返回对应的chunk在哪个chunkserver上,然后client再和chunkserver交互。
每个chunkserver直接使用linux的文件系统。
SLOG假设一个数据库系统是跑在横跨世界各地的数据中心的系统,这种系统我们通常称之为Geo-replicated Database Management System(DBMS),它将数据复制多份在各地的资料中心中。
数据库并发如果不做任何的控制,会破坏事务ACID特性的隔离性和一致性,如丢失修改、不可重复读、幻影现象和读“脏数据”等问题。
本文在mysql上验证快照隔离的特性。参考文章。